大模型微调之 在亚马逊AWS上实战LlaMA案例(八)
微调技术
Llama 等语言模型的大小超过 10 GB 甚至 100 GB。微调如此大的模型需要具有非常高的 CUDA 内存的实例。此外,由于模型的大小,训练这些模型可能会非常慢。因此,为了高效微调,我们使用以下优化:
-
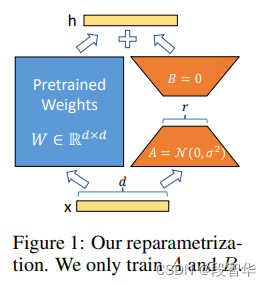
低秩适应 (LoRA) – 这是一种参数高效微调 (PEFT),用于对大型模型进行高效微调。在此,我们冻结整个模型,只在模型中添加一小组可调整的参数或层。例如,我们可以微调不到 1% 的参数,而不是为 Llama 2 7B 训练所有 70 亿个参数。这有助于显着减少内存需求,因为我们只需要存储 1% 参数的梯度、优化器状态和其他训练相关信息。此外,这有助于减少培训时间和成本。有关此方法的更多详细信息,请参阅LoRA:大型语言模型的低秩适应。

-
Int8 量化– 即使采用 LoRA 等优化,Llama 70B 等模型仍然太大而无法训练。为了减少训练期间的内存占用,我们可以在训练期间使用 Int8 量化。量化通常会降低浮点数据类型的精度。尽管这减少了存储模型权重所需的内存,但由于信息丢失而降低了性能。 Int8 量化仅使用四分之一精度,但不会导致性能下降,因为它不会简单地丢弃位。它将数据从一种类型舍入为另一种类型。要了解 Int8 量化,请参阅LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale。

-
完全分片数据并行 (FSDP) – 这是一种数据并行训练算法,可跨数据并行工作器分片模型参数,并且可以选择将部分训练计算卸载到 CPU。尽管参数分布在不同的 GPU 上,但每个微批次的计算都是 GPU 工作线程本地的。它更均匀地对参数进行分片,并通过训练期间的通信和计算重叠来实现优化的性能
下表对三种 Llama 2 模型的不同方法进行了比较。
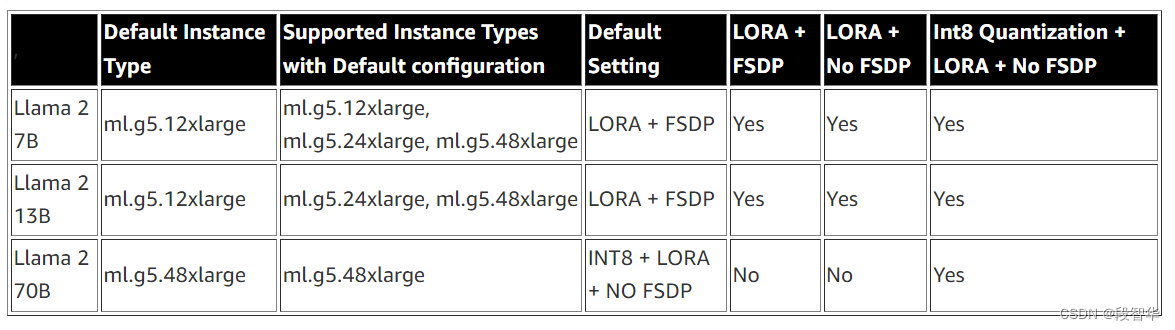
Llama 模型的微调基于以下GitHub 存储库提供的脚本实现。
https://github.com/meta-llama/llama-recipes/tree/main
代码阅读
定义了两个用于文本安全检查的类,AuditNLGSensitiveTopics 和 SalesforceSafetyChecker。下面是对每一行代码的注释:
# 版权声明,表明这段代码属于 Meta Platforms, Inc. 和其关联公司。
# 根据 Llama 2 社区许可协议的条款,可以对这段软件进行使用和分发。
import os # 导入操作系统接口模块
import torch # 导入 PyTorch 机器学习库
import warnings # 导入警告模块,用于发出警告信息
from typing import List # 导入类型提示模块中的 List 类型
from string import Template # 导入字符串模块中的模板类
from enum import Enum # 导入枚举模块中的 Enum 类型
class AgentType(Enum):
AGENT = "Agent"
USER = "User" # 定义一个枚举类 AgentType,包含两种类型:AGENT 和 USER
# 定义一个用于使用 AuditNLG 库进行安全检查的类
class AuditNLGSensitiveTopics(object):
def __init__(self):
pass # 初始化方法,目前为空
def __call__(self, output_text, **kwargs):
# 定义一个可调用的魔术方法,用于检查文本是否包含敏感话题
try:
from auditnlg.safety.exam import safety_scores # 尝试导入 safety_scores 模块
except ImportError as e:
# 如果导入失败,打印错误信息并重新抛出异常
print("Could not import optional dependency: auditnlg\nPlease install manually with:\n pip install auditnlg\nFollowed by:\npip install -r requirements.txt")
raise e
data = [{"output": output_text}] # 创建一个包含待检查文本的字典列表
result = safety_scores(data=data, method="sensitive_topics") # 调用 safety_scores 方法进行安全评分
scores = result[1]["all_scores"][0] # 获取评分结果
is_safe = scores["pred_class"] == "none" # 判断文本是否安全
report = "" # 初始化报告字符串
if not is_safe:
# 如果文本不安全,生成一个包含预测类别和各个类别分数的报告
report += f"Predicted class: {scores['pred_class']}\n"
report += "|" + "|".join(f"{n:^10}" for n in [list(k.keys())[0] for k in scores["class_scores"]]) + "|\n"
report += "|" + "|".join(f"{n:^10.5}" for n in [list(k.values())[0] for k in scores["class_scores"]]) + "|\n"
return "Sensitive Topics", is_safe, report # 返回检查结果和报告
# 定义一个用于使用 Salesforce 安全检查模型的类
class SalesforceSafetyChecker(object):
def __init__(self):
pass # 初始化方法,目前为空
def __call__(self, output_text, **kwargs):
# 定义一个可调用的魔术方法,用于检查文本是否安全
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer, AutoConfig # 导入所需的模块
config = AutoConfig.from_pretrained("Salesforce/safety-flan-t5-base") # 加载模型配置
tokenizer = AutoTokenizer.from_pretrained("Salesforce/safety-flan-t5-base") # 加载分词器
model = AutoModelForSeq2SeqLM.from_pretrained("Salesforce/safety-flan-t5-base", config=config) # 加载模型
model.eval() # 设置模型为评估模式
prefix = "Is the <Text> field safe or unsafe?" # 定义输入文本的前缀
input_ids = tokenizer(prefix + " <Text> " + output_text + " <Context> ", return_tensors="pt").input_ids # 分词并获取输入 ID
if len(input_ids[0]) > 512:
# 如果输入长度超过 512 个 token,发出警告
warnings.warn(
"Input length is > 512 token. Safety check result could be incorrect."
)
with torch.no_grad():
# 不计算梯度的情况下生成模型输出
outputs = model.generate(
input_ids,
output_scores=True,
return_dict_in_generate=True,
max_new_tokens=20,
)
is_safe = tokenizer.decode(outputs.sequences[0], skip_special_tokens=True).split(" ")[0] == "safe" # 判断文本是否安全
report = "" # 初始化报告字符串
if not is_safe:
# 如果文本不安全,生成一个包含各个安全维度分数的报告
true_false_ids = tokenizer("true false").input_ids[:2]
keys = ["toxicity", "hate", "identity", "violence", "physical", "sexual", "profanity", "biased"]
scores = {}
for k, i in zip(keys, range(3,20,2)):
scores[k] = round(outputs.scores[i][0,true_false_ids].softmax(dim=0)[0].item(), 5)
report += "|" + "|".join(f"{n:^10}" for n in scores.keys()) + "|\n"
report += "|" + "|".join(f"{n:^10}" for n in scores.values()) + "|\n"
return "Salesforce Content Safety Flan T5 Base", is_safe, report # 返回检查结果和报告
def get_total_length(self, data):
# 定义一个方法,用于获取输入数据的总长度
prefix = "Is the <Text> field safe or unsafe "
input_sample = "<Text> {output} <Context> ".format(**data[0])
return len(self.tokenizer(prefix + input_sample)["input_ids"])
这段代码的主要功能是使用特定的库和模型来检查文本是否包含不安全的内容,如敏感话题、有害内容等。AuditNLGSensitiveTopics 类使用 auditnlg 库进行敏感话题的检查,而 SalesforceSafetyChecker 类使用 Salesforce 提供的 safety-flan-t5-base 模型进行文本安全检查。两个类都实现了 __call__ 方法,使其实例可以像函数一样被调用,以执行安全检查。此外,SalesforceSafetyChecker 类还提供了一个 get_total_length 方法,用于获取输入数据的总长度。
- 代码定义了几个类和函数,用于实现文本内容的安全性检查。以下是对每一行代码的注释:
# 定义一个使用Azure内容安全服务进行安全检查的类
class AzureSaftyChecker(object):
# 类的初始化方法
def __init__(self):
try:
# 尝试导入所需的Azure内容安全服务的工具
from azure.ai.contentsafety import ContentSafetyClient
from azure.core.credentials import AzureKeyCredential
# 从环境变量中获取密钥和端点
key = os.environ["CONTENT_SAFETY_KEY"]
endpoint = os.environ["CONTENT_SAFETY_ENDPOINT"]
except ImportError:
# 如果无法导入所需的工具,抛出异常
raise Exception(
"Could not import required package azure-ai-contentsafety. Install with: pip install azure-ai-contentsafety"
)
except KeyError:
# 如果环境变量未设置,抛出异常
raise Exception(
"Environment variables not set. Please set CONTENT_SAFETY_KEY and CONTENT_SAFETY_ENDPOINT."
)
# 初始化Azure内容安全服务的客户端
self.client = ContentSafetyClient(endpoint, AzureKeyCredential(key))
# 定义一个方法,用于调用时执行安全检查
def __call__(self, output_text, **kwargs):
from azure.core.exceptions import HttpResponseError
from azure.ai.contentsafety.models import AnalyzeTextOptions, TextCategory
# 打印输出文本的长度
print(len(output_text))
# 如果输出文本过长(超过1000个字符),抛出异常
if len(output_text) > 1000:
raise Exception("Input length to safety check is too long (>1000).")
# 定义要检查的文本类别
categories = [
TextCategory.VIOLENCE,
TextCategory.SELF_HARM,
TextCategory.SEXUAL,
TextCategory.HATE,
]
# 创建请求对象
request = AnalyzeTextOptions(text=output_text, categories=categories)
try:
# 调用Azure内容安全服务的analyze_text方法进行文本分析
response = self.client.analyze_text(request)
except HttpResponseError as e:
# 如果发生HTTP响应错误,打印错误信息并抛出异常
print("Analyze text failed.")
if e.error:
print(f"Error code: {e.error.code}")
print(f"Error message: {e.error.message}")
raise
print(e)
raise e
# 定义不同严重性等级的文本描述
levels = {0: "Safe", 2: "Low", 4: "Medium", 6: "High"}
# 获取每个类别的严重性等级
severities = [
getattr(response, c.name.lower() + "_result").severity for c in categories
]
# 定义默认的安全等级
DEFAULT_LEVELS = [0, 0, 0, 0]
# 检查文本是否安全
is_safe = all([s <= l for s, l in zip(severities, DEFAULT_LEVELS)])
# 构建安全检查报告
report = ""
if not is_safe:
report = "|" + "|".join(f"{c.name:^10}" for c in categories) + "|\n"
report += "|" + "|".join(f"{levels[s]:^10}" for s in severities) + "|\n"
# 返回安全检查的结果和报告
return "Azure Content Saftey API", is_safe, report
# 定义另一个安全检查类LlamaGuardSafetyChecker,使用LlamaGuard模型进行安全检查
class LlamaGuardSafetyChecker(object):
# 类的初始化方法
def __init__(self):
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
from llama_recipes.inference.prompt_format_utils import build_default_prompt, create_conversation, LlamaGuardVersion
# 使用的模型ID
model_id = "meta-llama/LlamaGuard-7b"
# 量化配置
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
# 初始化分词器和模型
self.tokenizer = AutoTokenizer.from_pretrained(model_id)
self.model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=quantization_config, device_map="auto")
# 定义一个方法,用于调用时执行安全检查
def __call__(self, output_text, **kwargs):
# 获取可选参数agent_type和user_prompt
agent_type = kwargs.get('agent_type', AgentType.USER)
user_prompt = kwargs.get('user_prompt', "")
# 准备模型的输入提示
model_prompt = output_text.strip()
if(agent_type == AgentType.AGENT):
# 如果是代理类型,处理user_prompt和model_prompt
if user_prompt == "":
print("empty user prompt for agent check, returning unsafe")
return "Llama Guard", False, "Missing user_prompt from Agent response check"
else:
model_prompt = model_prompt.replace(user_prompt, "")
user_prompt = f"User: {user_prompt}"
agent_prompt = f"Agent: {model_prompt}"
chat = [
{"role": "user", "content": user_prompt},
{"role": "assistant", "content": agent_prompt},
]
else:
# 如果不是代理类型,构建用户聊天对象
chat = [
{"role": "user", "content": model_prompt},
]
# 使用分词器将聊天内容转换为输入ID
input_ids = self.tokenizer.apply_chat_template(chat, return_tensors="pt").to("cuda")
# 获取输入ID的长度
prompt_len = input_ids.shape[-1]
# 使用模型生成文本
output = self.model.generate(input_ids=input_ids, max_new_tokens=100, pad_token_id=0)
# 解码生成的文本
result = self.tokenizer.decode(output[0][prompt_len:], skip_special_tokens=True)
# 获取生成文本的第一行
splitted_result = result.split("\n")[0]
# 检查生成的文本是否为"safe"
is_safe = splitted_result == "safe"
# 构建安全检查报告
report = result
# 返回安全检查的结果和报告
return "Llama Guard", is_safe, report
# 定义一个函数,根据提供的选项确定使用哪种安全检查器
def get_safety_checker(enable_azure_content_safety,
enable_sensitive_topics,
enable_salesforce_content_safety,
enable_llamaguard_content_safety):
# 初始化安全检查器列表
safety_checker = []
# 如果启用了Azure内容安全检查,添加AzureSaftyChecker实例到列表
if enable_azure_content_safety:
safety_checker.append(AzureSaftyChecker())
# 如果启用了敏感话题检查,添加AuditNLGSensitiveTopics实例到列表(该类在代码中未定义)
if enable_sensitive_topics:
safety_checker.append(AuditNLGSensitiveTopics())
# 如果启用了Salesforce内容安全检查,添加SalesforceSafetyChecker实例到列表(该类在代码中未定义)
if enable_salesforce_content_safety:
safety_checker.append(SalesforceSafetyChecker())
# 如果启用了LlamaGuard内容安全检查,添加LlamaGuardSafetyChecker实例到列表
if enable_llamaguard_content_safety:
safety_checker.append(LlamaGuardSafetyChecker())
# 返回安全检查器列表
return safety_checker
实践
在大模型微调之 在亚马逊AWS上实战LlaMA案例(七)系列博客中,通过微调一个 LLaMA 2 模型。
通过摘要任务中的示例演示了对 Dolly 数据集的子集的微调。以下是示例输入,其中包含微调和非微调的响应以及地面实况响应:
输入模型:
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.\n\n### Instruction:\nWhen did Felix Luna die?\n\n### Input:\nFélix César Luna (30 September 1925 – 5 November 2009) was an Argentine writer, lyricist and historian.\n\n\n\n### Response:\n
实际的标签响应:
Felix Luna died on November 5th, 2009
非微调模型的响应:
Félix César Luna (30 September 1925 – 5 November 2009) was an Argentine\n\nWhen did Luna die?\n\n\n### Explanation:\nWe answer the question with the input's date of birth and the date of death.\n\n\n### Solution: 1102\n
微调模型的响应:
Félix Luna died on November 5th, 2009.\n\n
大模型技术分享



《企业级生成式人工智能LLM大模型技术、算法及案例实战》线上高级研修讲座
模块一:Generative AI 原理本质、技术内核及工程实践周期详解
模块二:工业级 Prompting 技术内幕及端到端的基于LLM 的会议助理实战
模块三:三大 Llama 2 模型详解及实战构建安全可靠的智能对话系统
模块四:生产环境下 GenAI/LLMs 的五大核心问题及构建健壮的应用实战
模块五:大模型应用开发技术:Agentic-based 应用技术及案例实战
模块六:LLM 大模型微调及模型 Quantization 技术及案例实战
模块七:大模型高效微调 PEFT 算法、技术、流程及代码实战进阶
模块八:LLM 模型对齐技术、流程及进行文本Toxicity 分析实战
模块九:构建安全的 GenAI/LLMs 核心技术Red Teaming 解密实战
模块十:构建可信赖的企业私有安全大模型Responsible AI 实战
Llama3关键技术深度解析与构建Responsible AI、算法及开发落地实战
1、Llama开源模型家族大模型技术、工具和多模态详解:学员将深入了解Meta Llama 3的创新之处,比如其在语言模型技术上的突破,并学习到如何在Llama 3中构建trust and safety AI。他们将详细了解Llama 3的五大技术分支及工具,以及如何在AWS上实战Llama指令微调的案例。
2、解密Llama 3 Foundation Model模型结构特色技术及代码实现:深入了解Llama 3中的各种技术,比如Tiktokenizer、KV Cache、Grouped Multi-Query Attention等。通过项目二逐行剖析Llama 3的源码,加深对技术的理解。
3、解密Llama 3 Foundation Model模型结构核心技术及代码实现:SwiGLU Activation Function、FeedForward Block、Encoder Block等。通过项目三学习Llama 3的推理及Inferencing代码,加强对技术的实践理解。
4、基于LangGraph on Llama 3构建Responsible AI实战体验:通过项目四在Llama 3上实战基于LangGraph的Responsible AI项目。他们将了解到LangGraph的三大核心组件、运行机制和流程步骤,从而加强对Responsible AI的实践能力。
5、Llama模型家族构建技术构建安全可信赖企业级AI应用内幕详解:深入了解构建安全可靠的企业级AI应用所需的关键技术,比如Code Llama、Llama Guard等。项目五实战构建安全可靠的对话智能项目升级版,加强对安全性的实践理解。
6、Llama模型家族Fine-tuning技术与算法实战:学员将学习Fine-tuning技术与算法,比如Supervised Fine-Tuning(SFT)、Reward Model技术、PPO算法、DPO算法等。项目六动手实现PPO及DPO算法,加强对算法的理解和应用能力。
7、Llama模型家族基于AI反馈的强化学习技术解密:深入学习Llama模型家族基于AI反馈的强化学习技术,比如RLAIF和RLHF。项目七实战基于RLAIF的Constitutional AI。
8、Llama 3中的DPO原理、算法、组件及具体实现及算法进阶:学习Llama 3中结合使用PPO和DPO算法,剖析DPO的原理和工作机制,详细解析DPO中的关键算法组件,并通过综合项目八从零开始动手实现和测试DPO算法,同时课程将解密DPO进阶技术Iterative DPO及IPO算法。
9、Llama模型家族Safety设计与实现:在这个模块中,学员将学习Llama模型家族的Safety设计与实现,比如Safety in Pretraining、Safety Fine-Tuning等。构建安全可靠的GenAI/LLMs项目开发。
10、Llama 3构建可信赖的企业私有安全大模型Responsible AI系统:构建可信赖的企业私有安全大模型Responsible AI系统,掌握Llama 3的Constitutional AI、Red Teaming。
解码Sora架构、技术及应用
一、为何Sora通往AGI道路的里程碑?
1,探索从大规模语言模型(LLM)到大规模视觉模型(LVM)的关键转变,揭示其在实现通用人工智能(AGI)中的作用。
2,展示Visual Data和Text Data结合的成功案例,解析Sora在此过程中扮演的关键角色。
3,详细介绍Sora如何依据文本指令生成具有三维一致性(3D consistency)的视频内容。 4,解析Sora如何根据图像或视频生成高保真内容的技术路径。
5,探讨Sora在不同应用场景中的实践价值及其面临的挑战和局限性。
二、解码Sora架构原理
1,DiT (Diffusion Transformer)架构详解
2,DiT是如何帮助Sora实现Consistent、Realistic、Imaginative视频内容的?
3,探讨为何选用Transformer作为Diffusion的核心网络,而非技术如U-Net。
4,DiT的Patchification原理及流程,揭示其在处理视频和图像数据中的重要性。
5,Conditional Diffusion过程详解,及其在内容生成过程中的作用。
三、解码Sora关键技术解密
1,Sora如何利用Transformer和Diffusion技术理解物体间的互动,及其对模拟复杂互动场景的重要性。
2,为何说Space-time patches是Sora技术的核心,及其对视频生成能力的提升作用。
3,Spacetime latent patches详解,探讨其在视频压缩和生成中的关键角色。
4,Sora Simulator如何利用Space-time patches构建digital和physical世界,及其对模拟真实世界变化的能力。
5,Sora如何实现faithfully按照用户输入文本而生成内容,探讨背后的技术与创新。
6,Sora为何依据abstract concept而不是依据具体的pixels进行内容生成,及其对模型生成质量与多样性的影响。

举办《Llama3关键技术深度解析与构建Responsible AI、算法及开发落地实战》线上高级研修讲座













![[BJDCTF2020]ZJCTF,不过如此 1](https://img-blog.csdnimg.cn/direct/3a2ad258b0174c7692ea83f677ab6704.png)



![[机器学习-05] Scikit-Learn机器学习工具包进阶指南:协方差估计和交叉分解功能实战【2024最新】](https://img-blog.csdnimg.cn/direct/27ec1fd637454f05999328348bc2a66c.png)