总结
本系列是机器学习课程的系列课程,主要介绍机器学习中图像文本检索技术。此技术把自然语言处理和图像处理进行了融合。
参考
2024年(第12届)“泰迪杯”数据挖掘挑战赛
图像特征提取(VGG和Resnet特征提取卷积过程详解)
2024 年(第 12 届)“泰迪杯”数据挖掘挑战赛——B 题:基于多模态特征融合的图像文本检索完整思路与源代码分享
【2024泰迪杯】B 题:基于多模态特征融合的图像文本检索Python代码实现
【2024泰迪杯】B 题:基于多模态特征融合的图像文本检索Python代码baseline
本门课程的目标
完成一个特定行业的算法应用全过程:
懂业务+会选择合适的算法+数据处理+算法训练+算法调优+算法融合
+算法评估+持续调优+工程化接口实现
机器学习定义
关于机器学习的定义,Tom Michael Mitchell的这段话被广泛引用:
对于某类任务T和性能度量P,如果一个计算机程序在T上其性能P随着经验E而自我完善,那么我们称这个计算机程序从经验E中学习。

基于多模态特征融合的图像文本检索
本文来源于2024年(第12届)“泰迪杯”数据挖掘挑战赛B题。
一、问题背景
随着近年来智能终端设备和多媒体社交网络平台的飞速发展,多媒体数据呈现海量增长的趋势,使当今主流的社交网络平台充斥着海量的文本、图像等多模态媒体数据,也使得人们对不同模态数据之间互相检索的需求不断增加。有效的信息检索和分析可以大大提高平台多模态数据的利用率及用户的使用体验,而不同模态间存在显著的语义鸿沟,大大制约了海量多模态数据的分析及有效信息挖掘。因此,在海量的数据中实现跨模态信息的精准检索就成为当今学术界面临的重要挑战。图像和文本作为信息传递过程中常见的两大模态,它们之间的交互检索不仅能有效打破视觉和语言之间的语义鸿沟和分布壁垒,还能促进许多应用的发展,如跨模态检索、图像标注、视觉问答等。
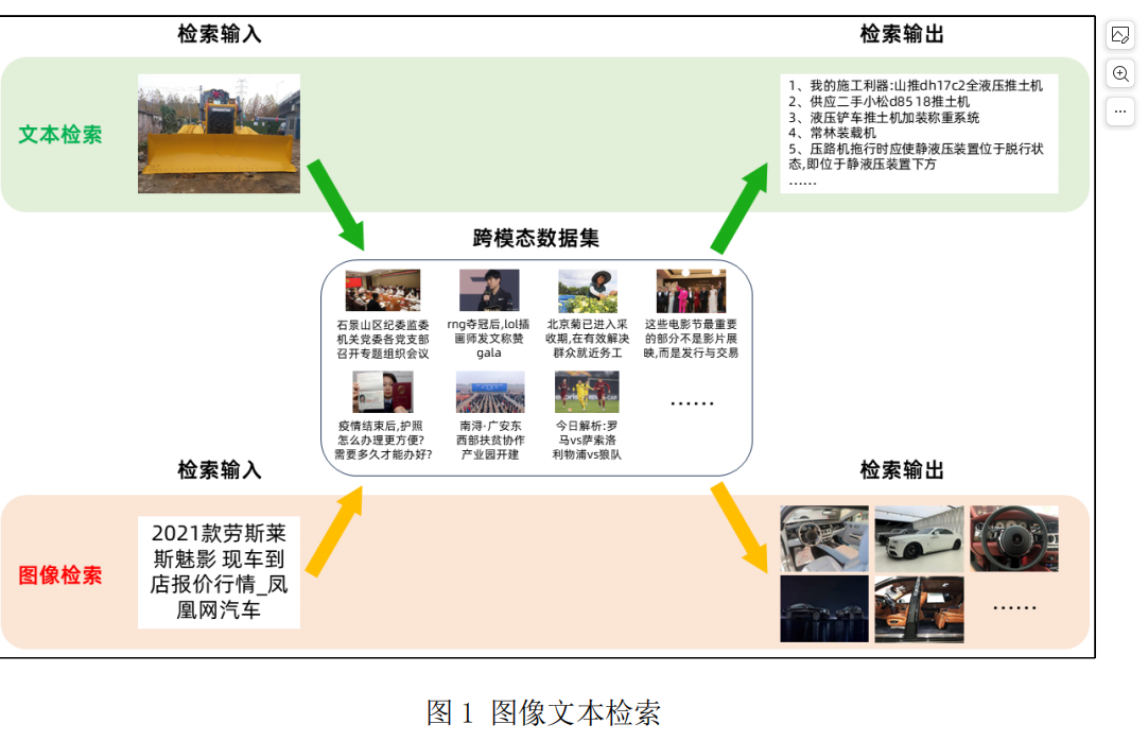
图像文本检索指的是输入某一模态的数据(例如图像),通过训练的模型自动检索出与之最相关的另一模态数据(例如文本),它包括两个方向的检索,即基于文本的图像检索和基于图像的文本检索,如图1所示。基于文本的图像检索的目的是从数据库中找到与输入句子相匹配的图像作为输出结果;基于图像的文本检索根据输入图片,模型从数据库中自动检索出能够准确描述图片内容的文字。然而,来自图像和来自文本的特征存在固有的数据分布的差异,也被称为模态间的“异构鸿沟”,使得度量图像和文本之间的语义相关性困难重重。
二、解决问题
本赛题是利用附件1的数据集,选择合适方法进行图像和文本的特征提取,基于提取的特征数据,建立适用于图像检索的多模态特征融合模型和算法,以及建立适用于文本检索的多模态特征融合模型和算法。
基于建立的“多模态特征融合的图像文本检索”模型,完成以下两个任务,并提交相关材料。
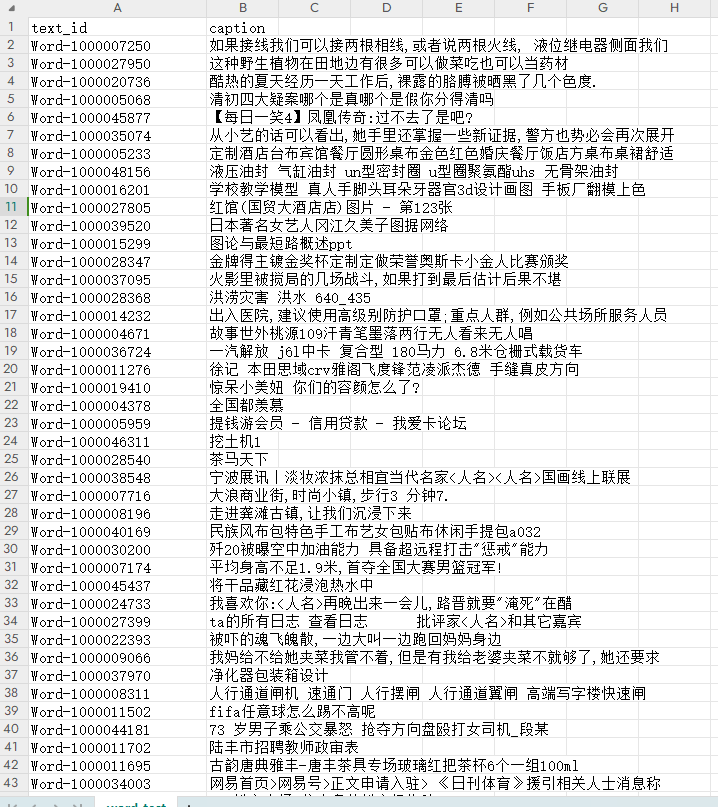
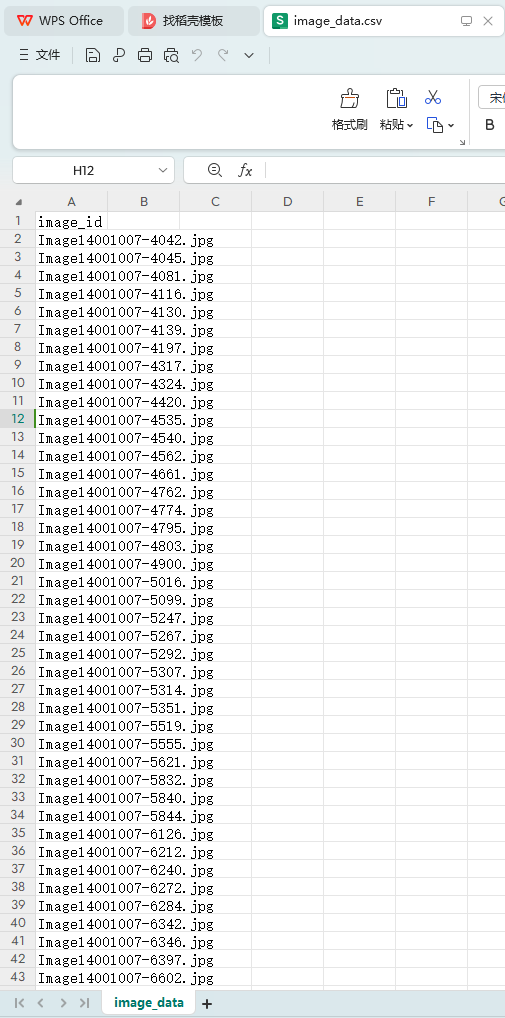
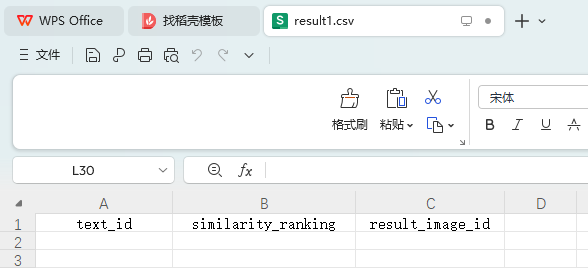
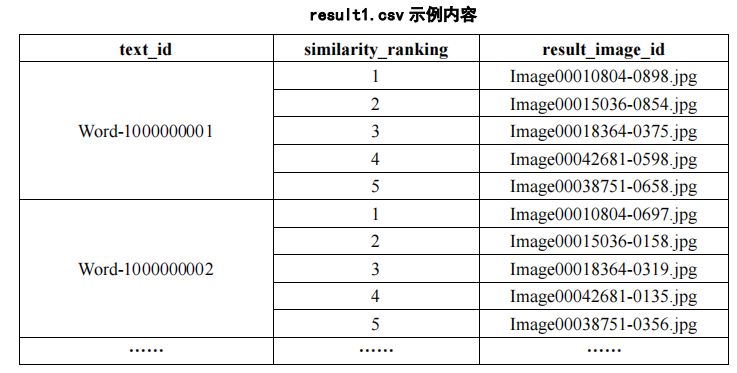
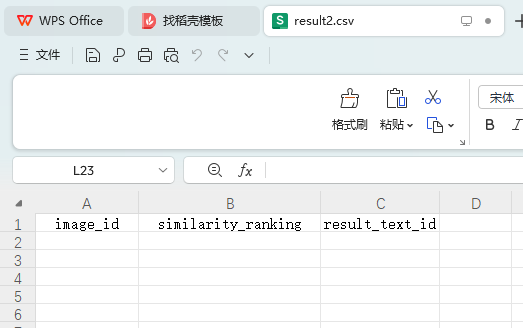
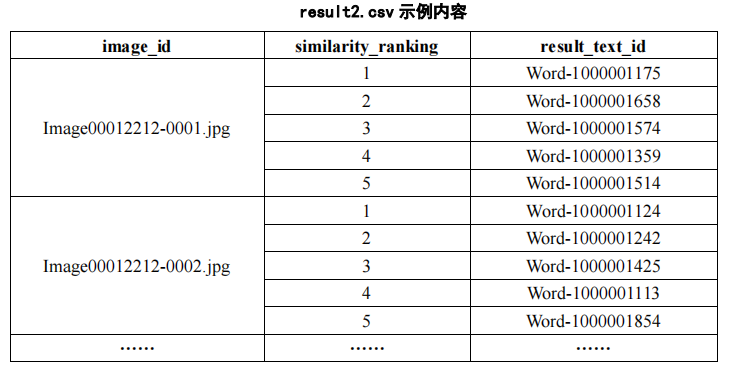
(1)基于图像检索的模型和算法,利用附件2中“word_test.csv”文件的文本信息,对附件2的ImageData文件夹的图像进行图像检索,并罗列检索相似度较高的前五张图像,将结果存放在“result1.csv”文件中(模板文件详见附件4的result1.csv)。其中,ImageData文件夹中的图像ID详见附件2的“image_data.csv”文件。
(2)基于文本检索的模型和算法,利用附件3中“image_test.csv”文件提及的图像ID,对附件3的“word_data.csv”文件进行文本检索,并罗列检索相似度较高的前五条文本,将结果存放在“result2.csv”文件中(模板文件见附件4的result2.csv)。其中,“image_test.csv”文件提及的图像id,对应的图像数据可在附件3的ImageData文件夹中获取。
三、评价标准

四、问题分析
这个问题分成两个部分来分析:图像检索的多模态特征融合模型和算法,以及文本检索的多模态特征融合模型和算法。
(1)图像特征提取
首先,需要选择合适的方法对图像进行特征提取,常见的图像特征提取方法包括:SIFT(尺度不变特征转换)、SURF(加速稳健特征)、HOG(方向梯度直方图)、CNN(卷积神经网络)等
(2)文本特征提取
对于文本数据,可以使用传统的词袋模型或者更加先进的词嵌入模型(如Word2Vec、FastText等)来提取文本特征。
(3)多模态特征融合模型和算法
分别得到图像和文本的特征后,建立一个多模态特征融合模型来整合这些特征。常见的模型包括:向量拼接(Concatenation)、双向编码器(Bi-Encoder)、Transformer 模型、多层感知机(MLP)、注意力机制(Attention)
(4)特定的损失函数
在多模态的模型中,需要考虑对应的损失函数(如Triplet Loss、Contrastive Loss等)来训练模型,使得模型能够更好地学习多模态特征融合的表示能力。
五、多模态的参考论文及代码
(1) “X-ModalNet: A Semi-Paired Cross-Modal Network for RGB-D Salient Object Detection” (2019)
提出了一种半配对跨模态网络(X-ModalNet),用于RGB-D显著对象检测任务。网络利用跨模态交叉注意力来增强特征表达,并融合来自不同模态的信息。
代码:https://github.com/CommonClimate/CCA?utm_source=catalyzex.com
(2)SMAN: Stacked multimodal attention network for cross-modal image–text retrieval
(3)Deep canonical correlation analysis with progressive and hypergraph learning for cross-modal retrieval
(4)Multi-view multi-label canonical correlation analysis for cross-modal matching and retrieval
代码:https://github.com/Rushil231100/MVMLCCA
(5)Multi-scale image–text matching network for scene and spatio-temporal images
(6)Stacked Cross Attention for Image-Text Matching
代码:https://github.com/kuanghuei/SCAN
(7)Look, Imagine and Match: Improving Textual-Visual Cross-Modal Retrieval with Generative Models
提出利用生成模型来提升文本视觉跨模态检索。LIM模型首先观察图像,然后想象与文本匹配的视觉内容,最后匹配对应的特征。
(8)Adaptive Text Recognition through Visual Matching
代码:https://github.com/tesseract-ocr/tessdoc
(9)LXMERT: Learning Cross-Modality Encoder Representations from Transformers
代码:https://paperswithcode.com/paper/lxmert-learning-cross-modality-encoder
(10)Learning rich touch representations through cross-modal self-supervision
代码:https://github.com/google-deepmind/deepmind-research
(11)CLaMP: Contrastive Language-Music Pre-training for Cross-Modal Symbolic Music Information Retrieval
代码:https://github.com/microsoft/muzic
(12)UniXcoder: Unified Cross-Modal Pre-training for Code Representation
代码:https://github.com/microsoft/CodeBERT
(13)mPLUG: Effective and Efficient Vision-Language Learning by Cross-modal Skip-connections
代码:https://paperswithcode.com/paper/mplug-effective-and-efficient-vision-language
六、建立的“多模态特征融合的图像文本检索”模型。
任务1.思路
1.数据加载与预处理:
通过读取CSV文件,加载图像数据集和对应的文本描述。
设置图像文件夹的路径,用于加载图像文件。
2.特征提取:
使用预训练的VGG16模型提取图像特征。VGG16是一个常用的深度学习模型,在ImageNet数据集上进行了训练,可提取图像的高级语义特征。
利用预训练的Word2Vec模型提取文本特征。Word2Vec是一个常用的词向量模型,可以将文本转换为密集向量表示,捕捉词语之间的语义关系。
3.特征融合:
将提取的图像特征和文本特征拼接在一起,形成多模态特征表示。
在这个示例中,使用了简单的拼接方式,将图像特征和文本特征直接连接在一起作为模型的输入。
4.模型训练与测试:
将数据集划分为训练集和测试集,使用划分后的数据训练多模态特征融合模型。
在这个示例中,使用了支持向量机(SVM)作为分类器,并在训练过程中加入了PCA降维处理以减少特征维度。
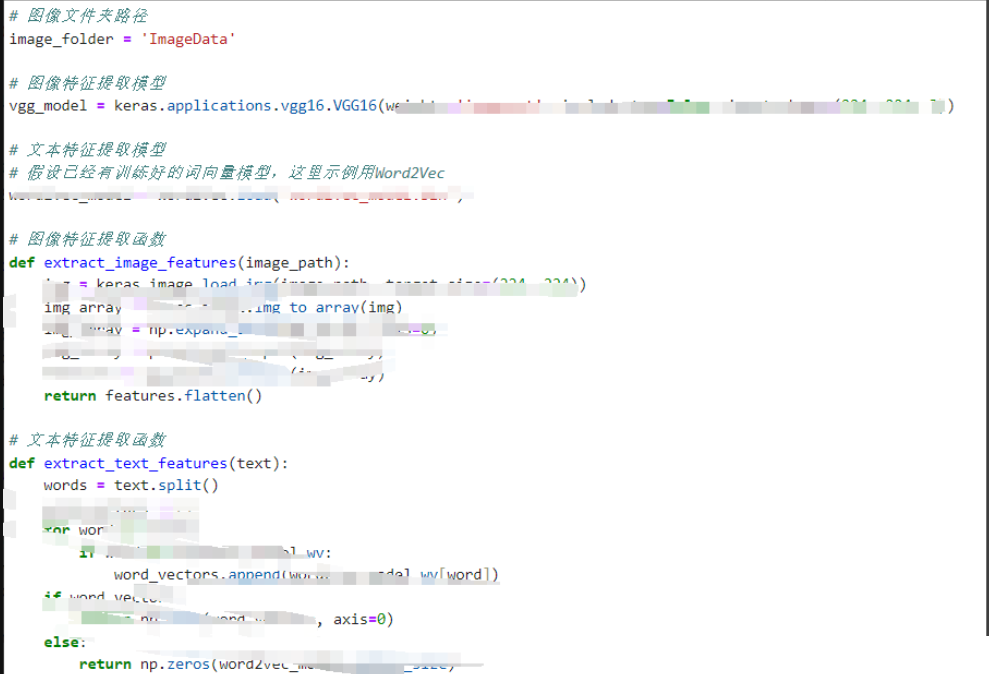

图像特征提取:
使用预训练的深度学习模型(如VGG、ResNet、Inception等)来提取图像的特征。这些模型在大规模图像数据集上进行了训练,并能够捕获图像的高级语义信息。
从每个图像中提取出的特征应该是一个固定长度的向量,表示图像的语义信息。
文本特征提取:
对文本数据进行处理,可以使用词嵌入模型(如Word2Vec、GloVe、BERT等)来将文本转换为向量表示。
对于每个文本,可以通过将词向量进行平均或加权平均来得到整个文本的向量表示。
特征融合:
将图像特征和文本特征进行融合,形成多模态特征表示。融合可以采用简单的拼接、加权平均等方式。
融合后的特征向量将包含图像和文本的语义信息,有助于更好地表示多模态数据。
相似度计算:
使用合适的相似度计算方法(如余弦相似度、欧氏距离等),计算图像与文本之间的相似度。相似度计算时应该基于融合后的特征向量。
相似度的计算可以使用最近邻算法(如k近邻)、基于距离的方法等。
任务2 思路
基于文本检索的模型和算法,利用附件 3 中“image_test.csv”文件提及的图像ID,对附件 3 的“word_data.csv”文件进行文本检索,并罗列检索相似度较高的前五条文本,将结果存放在“result2.csv”文件中(模板文件见附件 4 的 result2.csv)。其中,“image_test.csv”文件提及的图像 id,对应的图像数据可在附件 3 的 ImageData 文件夹中获取(完整附件见文末)
1.文本特征提取:
对附件3中的文本数据进行特征提取。可以使用预训练的词向量模型(如Word2Vec、GloVe等)将文本转换为向量表示,也可以使用文本嵌入技术(如BERT、ELMo等)获取文本的高级语义特征。
2.图像特征提取:
从附件3的ImageData文件夹中加载与图像ID对应的图像数据。然后,使用图像处理技术(如深度学习模型)提取图像的特征表示。
3.特征融合:
将文本特征和图像特征进行融合,形成多模态特征表示。可以简单地将两者连接在一起,也可以通过某些模型(如多层感知器、注意力机制等)进行融合。
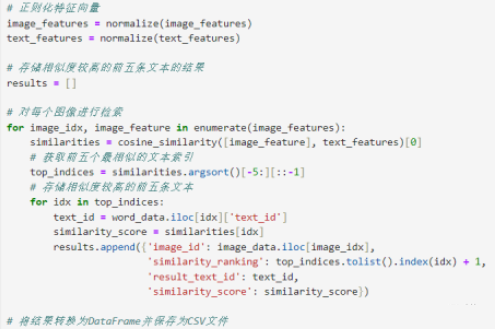
4.相似度计算:
使用合适的相似度计算方法(如余弦相似度、欧氏距离等)来衡量图像与文本之间的相似度。较高的相似度表明图像与文本之间的语义关联性更强。
5.结果展示:
将相似度较高的前五条文本列出,并将结果存储在指定的CSV文件中,以便后续提交。每个图像ID都会有与之相关的文本ID列表。
七、python代码实现




任务一
方法一:从0训练一个模型
要求实现,对附件2中的word_test.csv中的每行文本,从附件2的imageData文件夹中检索出最相似的5张图片,并按相似度排序,用序号表示。首先需要用附件1中的ImageWordData.csv和附件1中的ImageData作为训练集,训练多模态模型,然后用来测试附件2中的数据。
(1)导入包
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.models as models
import torchvision.transforms as transforms
from PIL import Image
import pandas as pd
import csv
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
from gensim.models import Word2Vec,KeyedVectors
import jieba
import gensim
import os
import torch.nn.functional as F
(2)处理文本训练数据.
# 处理文本数据
text_df1 = pd.read_csv("附件1/ImageWordData.csv")
# 定义中文分词函数
def Chinese_tokenizer(text):
return list(jieba.cut(text))
# 对caption进行中文分词
text_data1 = text_df1['caption'].apply(Chinese_tokenizer).tolist()
# 由于加载word2vec非常费时,需要向量本地化
file_path = "word2vec/train_vocabulary_vector.csv"
if os.path.exists(file_path):
# 读取词汇-向量字典,csv转字典
vocabulary_vector = dict(pd.read_csv("word2vec/train_vocabulary_vector.csv"))
# 此时需要将字典中的词向量np.array型数据还原为原始类型,方便以后使用
for key,value in vocabulary_vector.items():
vocabulary_vector[key] = np.array(value)
word2vec_model = KeyedVectors.load('hy-tmp/train_bio_word',mmap='r')
else:
# 读取中文词向量模型(需要提前下载对应的词向量模型文件)
word2vec_model = KeyedVectors.load_word2vec_format('hy-tmp/word2vec.bz2', binary=False)
word2vec_model.init_sims(replace=True)
word2vec_model.save('hy-tmp/train_bio_word')
# 所有文本构建词汇表,words_cut 为分词后的list,每个元素为以空格分隔的str.
vocabulary = list(set([word for item in text_data1 for word in item]))
# 构建词汇-向量字典
vocabulary_vector = {}
for word in vocabulary:
if word in word2vec_model:
vocabulary_vector[word] = word2vec_model[word]
# 储存词汇-向量字典,由于json文件不能很好的保存numpy词向量,故使用csv保存
pd.DataFrame(vocabulary_vector).to_csv("word2vec/train_vocabulary_vector.csv")
(3)处理图像数据
# 处理图像数据
image_df = pd.read_csv("附件1/ImageWordData.csv")
image_data = image_df['image_id'].tolist()
# 数据预处理和加载
transform = transforms.Compose([
transforms.Resize((224, 224)), # 根据模型的要求进行图像尺寸调整
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 根据模型的要求进行图像归一化
])
(4)定义多模态的训练模型和损失函数
class ImageEncoder(nn.Module):
def __init__(self, out_dim=128):
super(ImageEncoder, self).__init__()
self.cnn = models.resnet18(pretrained=True)
self.fc = nn.Linear(512, out_dim)
def forward(self, x):
with torch.no_grad():
x = self.cnn.conv1(x)
x = self.cnn.bn1(x)
x = self.cnn.relu(x)
x = self.cnn.maxpool(x)
x = self.cnn.layer1(x)
x = self.cnn.layer2(x)
x = self.cnn.layer3(x)
x = self.cnn.layer4(x)
x = F.adaptive_avg_pool2d(x, (1, 1))
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
class TextEncoder(nn.Module):
def __init__(self,embedding_dim):
super(TextEncoder, self).__init__()
self.rnn = nn.LSTM(embedding_dim, 128, batch_first=True)
def forward(self, x):
# x = x.to(device)
_, (x, __) = self.rnn(x)
x = x.squeeze(1)
return x
class MultimodalCnn(nn.Module):
...略
return fusion
# 定义对比损失函数
class ContrastiveLoss(nn.Module):
def __init__(self, margin=2.0):
super(ContrastiveLoss, self).__init__()
self.margin = margin
def forward(self, output1, output2, label):
euclidean_distance = F.pairwise_distance(output1, output2, keepdim=True)
loss_contrastive = torch.mean((1-label) * torch.pow(euclidean_distance, 2) +
(label) * torch.pow(torch.clamp(self.margin - euclidean_distance, min=0.0), 2))
return loss_contrastive
# 定义欧氏距离损失函数
class EuclideanDistanceLoss(nn.Module):
def __init__(self):
super(EuclideanDistanceLoss, self).__init__()
def forward(self, output1, output2, label):
euclidean_distance = F.pairwise_distance(output1, output2, keepdim=True)
loss = torch.mean(torch.pow(euclidean_distance - label, 2))
return loss
class CosineDistanceLoss(nn.Module):
def __init__(self, margin=0.5):
super(CosineDistanceLoss, self).__init__()
self.margin = margin
def forward(self, output1, output2, label):
cos_sim = F.cosine_similarity(output1, output2)
loss = torch.mean((1 - label) * torch.pow(cos_sim, 2) + label * torch.pow(torch.clamp(self.margin - cos_sim, min=0.0), 2))
return loss
(4)模型训练
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 训练模型权重
image_encoder = ImageEncoder().to(device)
text_encoder = TextEncoder(embedding_dim=300).to(device)
model = MultimodalCnn(image_encoder, text_encoder).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 迭代训练模型
num_epochs = 5
# 实例化对比损失函数
# criterion = ContrastiveLoss(margin=2.0)
# 欧式距离损失函数
# criterion = EuclideanDistanceLoss()
criterion = CosineDistanceLoss()
for epoch in range(num_epochs):
running_loss = 0.0
for i, (image, text) in enumerate(zip(image_data, text_data1)):
# 加载图像
image_path = "附件1/ImageData/" + image # 图像文件夹路径
img = Image.open(image_path)
if img.mode != 'RGB':
# 如果图片不是RGB格式,先转换为RGB格式
img = img.convert('RGB')
img = transform(img).unsqueeze(0).to(device)
# 加载文本
sentence_vec = [torch.tensor(vocabulary_vector[word], dtype=torch.float) for word in text if word in vocabulary_vector]
# 计算句子中每个分词向量的平均值,并将结果转换为torch张量
if len(sentence_vec)>0:
text_sequence = torch.stack(sentence_vec).unsqueeze(0).to(device)
optimizer.zero_grad()
# 正向传播
...略
# 反向传播和优化
loss.backward() # 反向传播
optimizer.step() # 更新权重
running_loss += loss.item()
else:
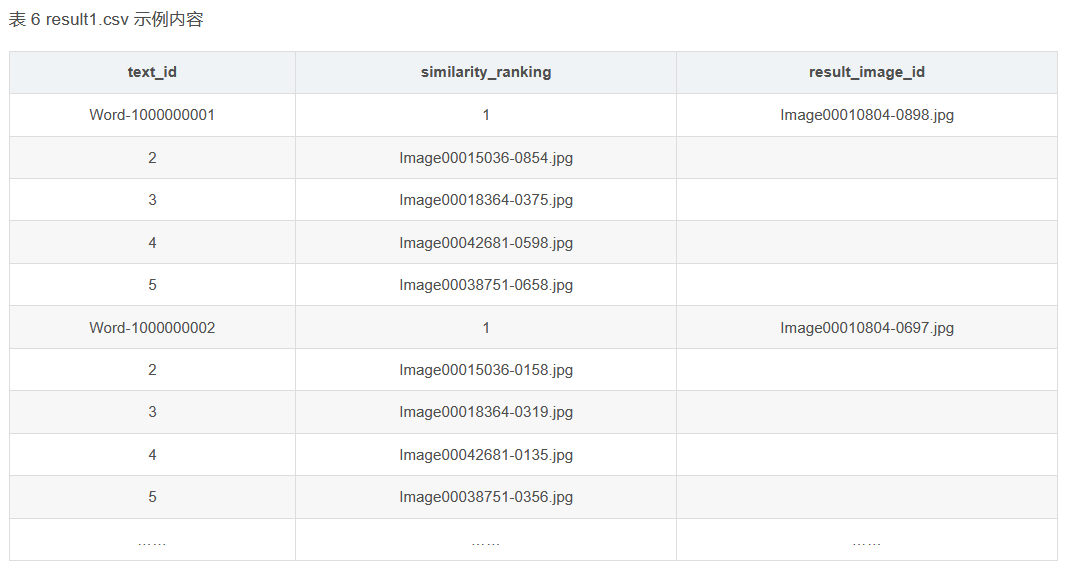
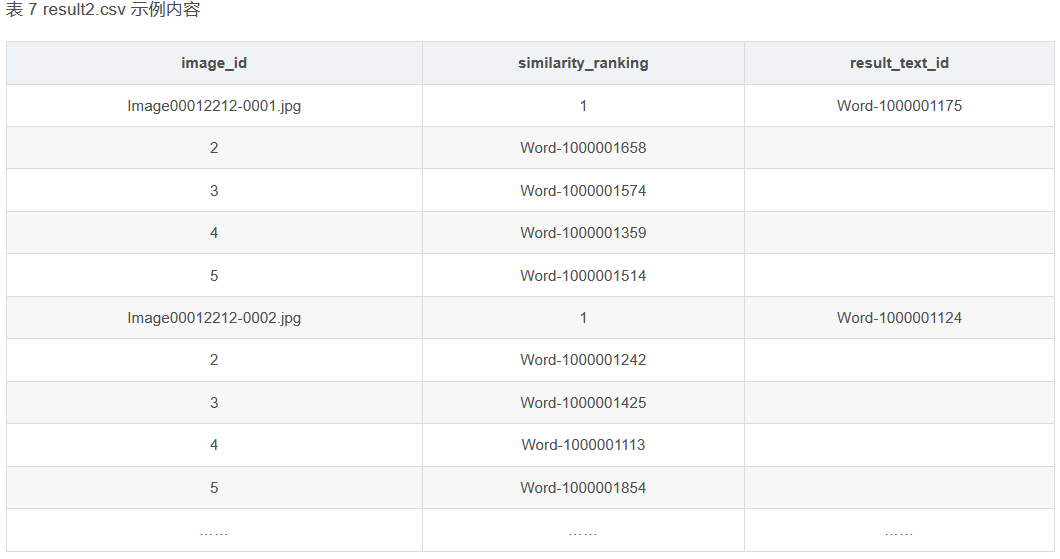
# 这些是没有向量的文本
print(text)
# 打印每个epoch的损失
print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss / len(image_data)}")
# 保存模型权重
torch.save(model.state_dict(), 'models/multimodal_cnn_weights.pth')
(5)模型测试
# 处理文本数据
text_df = pd.read_csv("附件2/word_test.csv")
# 定义中文分词函数
def Chinese_tokenizer(text):
return list(jieba.cut(text))
# 对caption进行中文分词
text_data = text_df['caption'].apply(Chinese_tokenizer).tolist()
# 由于加载word2vec非常费时,需要向量本地化
file_path = "word2vec/test_vocabulary_vector.csv"
if os.path.exists(file_path):
# 读取词汇-向量字典,csv转字典
vocabulary_vector = dict(pd.read_csv("word2vec/test_vocabulary_vector.csv"))
# 此时需要将字典中的词向量np.array型数据还原为原始类型,方便以后使用
for key,value in vocabulary_vector.items():
vocabulary_vector[key] = np.array(value)
word2vec_model = KeyedVectors.load('hy-tmp/test_bio_word',mmap='r')
else:
# 读取中文词向量模型(需要提前下载对应的词向量模型文件)
word2vec_model = KeyedVectors.load_word2vec_format('hy-tmp/word2vec.bz2', binary=False)
word2vec_model.init_sims(replace=True)
word2vec_model.save('hy-tmp/bio_word')
# 所有文本构建词汇表,words_cut 为分词后的list,每个元素为以空格分隔的str.
vocabulary = list(set([word for item in text_data for word in item]))
# 构建词汇-向量字典
vocabulary_vector = {}
for word in vocabulary:
if word in word2vec_model:
vocabulary_vector[word] = word2vec_model[word]
# 储存词汇-向量字典,由于json文件不能很好的保存numpy词向量,故使用csv保存
pd.DataFrame(vocabulary_vector).to_csv("word2vec/test_vocabulary_vector.csv")
# 处理图像数据
image_df = pd.read_csv("附件2/image_data.csv")
image_data = image_df['image_id'].tolist()
# 加载模型和权重
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
image_encoder = ImageEncoder().to(device)
text_encoder = TextEncoder(embedding_dim=300).to(device)
model = MultimodalCnn(image_encoder, text_encoder).to(device)
model.load_state_dict(torch.load('models/multimodal_cnn_weights.pth')) # 加载预训练权重
(6)计算文本向量和图像向量相似度
from collections import defaultdict
d2 = defaultdict(list)
# 存储相似度
similarity_ranking = []
result_image_id = []
similarity_list = defaultdict(list)
k =1
# 图像检索
for text_id,text in zip(text_df['text_id'],text_data):
print(f'{k}/{len(text_data)}')
k+=1
# 加载文本
sentence_vec = [torch.tensor(vocabulary_vector[word], dtype=torch.float) for word in text if word in vocabulary_vector]
# 计算句子中每个分词向量的平均值,并将结果转换为torch张量
text_sequence = torch.stack(sentence_vec).unsqueeze(0).to(device)
text_features = model.text_encoder(text_sequence)
text_features = text_features.to("cpu").detach().numpy()
for image_id in image_data:
image_path = f"附件2/ImageData/{image_id}"
image = Image.open(image_path).convert('RGB')
image = transform(image).unsqueeze(0).to(device)
image_features = model.image_encoder(image)
image_features = image_features.to("cpu").detach().numpy()
similarity = cosine_similarity(text_features, image_features)
similarity_list[text_id].append(similarity)
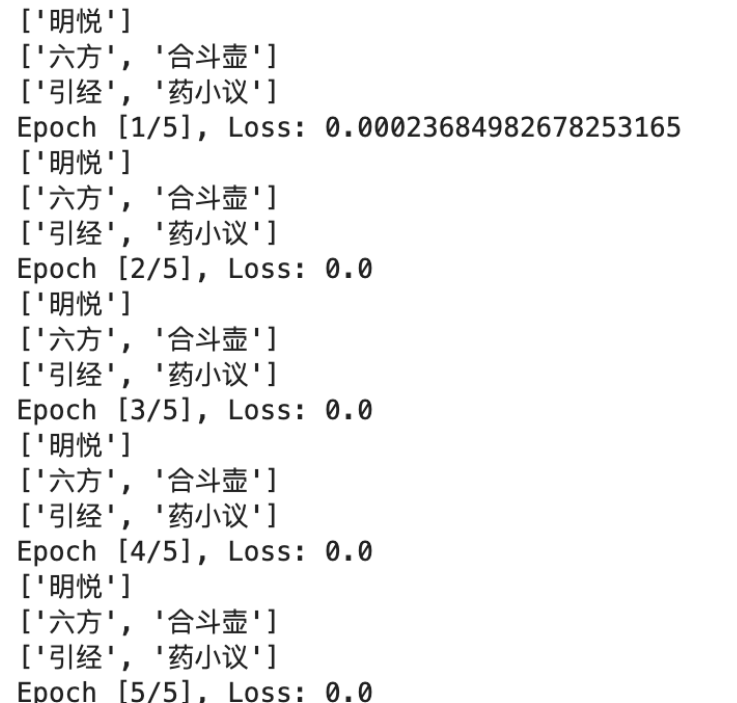
(7)选出最相似的五张图片
# 选出前5张最相似的图片
result = []
for key, value_list in similarity_list.items():
sorted_value_list = sorted(value_list, reverse=True)
top_three_values = sorted_value_list[:5]
for value in top_three_values:
index = value_list.index(value)
id_value = image_data[index]
rank = top_three_values.index(value) + 1
result.append([key, id_value, rank])
result
(8)存储为result1.csv
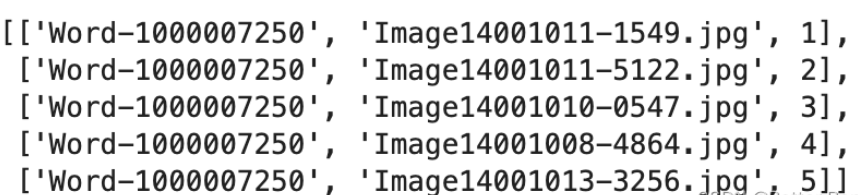
# 将结果存放到result1.csv文件中
result_df = pd.DataFrame(result, columns=['text_id', 'similarity_ranking', 'result_image_id'])
result_df.to_csv('result1.csv', index=False)
方法二:使用预训练模型
采用Huggingface上预训练的多模态模型,零样本计算处理文本和图像数据,并计算其相似度,选择相似度最高的5张图片。
import os
import pandas as pd
from PIL import Image
import torch
import warnings
warnings.filterwarnings('ignore')
text_test_csv = "示例数据/附件2/word_test.csv"
image_data_csv = "示例数据/附件2/image_data.csv"
image_folder = "示例数据/附件2/ImageData/"
output_csv = "result_data/result1.csv"
# 读取文本和图像数据
text_data = pd.read_csv(text_test_csv)
image_data = pd.read_csv(image_data_csv)
# 初始化模型和处理器
model =...略
processor = ...略
# 处理文本并生成特征
text_inputs = processor(text=text_data['caption'].tolist(),padding=True,return_tensors="pt")
with torch.no_grad():
text_features = model.get_text_features(**text_inputs).cpu()
# 处理每张图像并生成特征
image_features_list = []
for image_id in image_data['image_id']:
image_path = os.path.join(image_folder,image_id)
image = Image.open(image_path)
image_inputs = processor(images=image,return_tensors="pt")
with torch.no_grad():
image_features = model.get_image_features(**image_inputs).cpu()
image_features_list.append(image_features)
image_features = torch.vstack(image_features_list) # 合并为一个Tensor
# 归一化特征向量
image_features = image_features / image_features.norm(dim=1,keepdim=True)
text_features = text_features / text_features.norm(dim=1,keepdim=True)
# 计算文本和图像间的相似度
similarity = text_features @ image_features.T
# 找到最相似的前五张图片
result_records = []
for i,sims in enumerate(similarity):
top_indices = sims.topk(5).indices
for rank,idx in enumerate(top_indices):
result_records.append({
"text_id":text_data.iloc[i]['text_id'],
"similarity_ranking":rank + 1,
"result_image_id":image_data.iloc[int(idx)]['image_id']
})
# 保存到CSV文件
result_df = pd.DataFrame(result_records)
result_df.to_csv(output_csv,index=False)
print(f"图像检索完成,结果已保存到 {output_csv}")
result_df
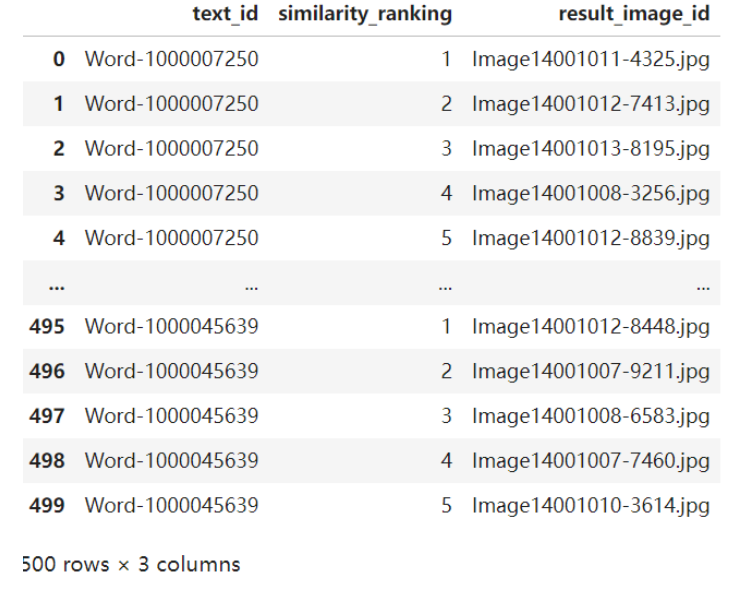
import pandas as pd
import os
from PIL import Image
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import warnings
warnings.filterwarnings('ignore')
font_path = '/示例数据/SimHei.ttf'
prop = fm.FontProperties(fname=font_path)
# plt.rcParams['font.sans-serif'] = 'Microsoft YaHei'
result1_csv = "result_data/result1.csv"
# 读取result_df表格
result_df = pd.read_csv(result1_csv)
# 读取ImageData 2文件夹中的图片
image_folder = '示例数据/附件2/ImageData'
image_paths = [os.path.join(image_folder,f'{row["result_image_id"]}') for _,row in result_df.iterrows()]
images = [Image.open(image_path) for image_path in image_paths]
# 读取word_test.csv文件的文本信息
text_df = pd.read_csv('示例数据/附件2/word_test.csv')
# 将文本信息与result_df表格合并
result_df = result_df.merge(text_df,on='text_id')
fig,axs = plt.subplots(5,2,figsize=(10,20))
for i in range(10):
row = result_df.iloc[i]
image = images[i]
text = row['caption']
ax = axs[i // 2,i % 2]
ax.imshow(image)
ax.set_title(f'Similarity Ranking:{row["similarity_ranking"]}\nText:{text}',fontproperties=prop)
ax.axis('off')
plt.savefig('result_data/result1.png',dpi=300)
plt.show()


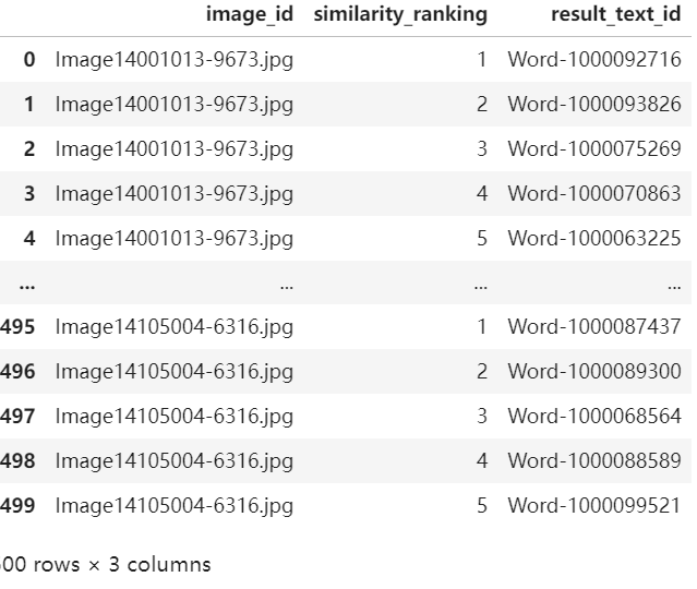
任务二
import pandas as pd
from PIL import Image
import torch
import warnings
warnings.filterwarnings('ignore')
# 文件路径定义
image_test_csv = "/示例数据/附件3/image_test.csv"
word_data_csv = "/示例数据/附件3/word_data.csv"
image_folder = "/示例数据/附件3/ImageData/"
output_csv = "result_data/result2.csv"
# 加载模型
text_model = ...略
vision_model = ...略
processor = ...略
# 读取文本数据
word_data = pd.read_csv(word_data_csv)
word_data['caption'] = word_data['caption'].astype(str)
# 处理文本
text_inputs = processor(text=word_data['caption'].tolist(),padding=True,return_tensors="pt",max_length=32,truncation=True).input_ids
# # 计算文本特征
with torch.no_grad():
text_features = text_model(text_inputs).pooler_output
text_features /= text_features.norm(dim=1,keepdim=True)
# 读取图像ID
image_test = pd.read_csv(image_test_csv)
# 结果列表
results = []
# 遍历每个图像
for image_id in image_test['image_id']:
# 加载图像
image_path = f"{image_folder}{image_id}"
image = Image.open(image_path).convert("RGB")
# 处理图像
vision_inputs = processor(images=image,return_tensors="pt")
# 计算图像特征
with torch.no_grad():
vision_features = vision_model(**vision_inputs).pooler_output
vision_features /= vision_features.norm(dim=1,keepdim=True)
# 计算文本图像之间的余弦相似度
similarities = (vision_features @ text_features.T).squeeze(0)
# 获取相似度最高的5个文本
top5_indices = similarities.topk(5).indices
# 存储结果
for rank,index in enumerate(top5_indices):
results.append({
"image_id":image_id,
"similarity_ranking":rank + 1,
"result_text_id":word_data.iloc[int(index)]['text_id']
})
print("检索完成")
result_df = pd.DataFrame(results)
# 将结果存储到 CSV 文件
result_df = pd.DataFrame(results)
result_df.to_csv(output_csv,index=False)
print("结果已保存到",output_csv)
result_df
import pandas as pd
import os
import matplotlib.pyplot as plt
from PIL import Image
import matplotlib.font_manager as fm
import cv2
font_path = '/示例数据/SimHei.ttf'
prop = fm.FontProperties(fname=font_path)
result2_csv = "result2.csv"
word_data_csv = "/示例数据/附件3/word_data.csv"
image_folder = "/示例数据/附件3/ImageData/"
# 读取result_df表格
result_df = pd.read_csv(result2_csv)
# 读取word_data.csv文件
word_data_df = pd.read_csv(word_data_csv)
# 预处理数据,只处理前20行数据
result_df = result_df.head(20)
# 设置画板尺寸
plt.figure(figsize=(10,25))
# 遍历前20行数据
for i in range(0,20,5):
# 获取图像路径和对应的5个text_id
image_path = os.path.join(image_folder,result_df.iloc[i]["image_id"])
text_ids = result_df.iloc[i:i+5]['result_text_id']
# 读取图片
image = Image.open(image_path)
# 创建子图(图在左,文本在右)
plt.subplot(5,1,(i//5) + 1)
# 显示图片
plt.imshow(image)
plt.axis('off') # 不显示坐标轴
# 显示对应的文本
for j, text_id in enumerate(text_ids):
# 获取文本内容
caption = word_data.loc[word_data['text_id'] == text_id, 'caption'].values[0]
# 在图片右侧添加文本
plt.text(image.width + 10, image.height/ 6 * j, caption, va='top',fontproperties=prop)
# 调整各子图间距
plt.tight_layout()
# 显示整个画板
plt.show()

从任务一的结果图中可以看到,直接使用预训练模型,效果是比较理想的,但是在任务二中,如果模型不微调,直接使用,效果是非常差。需要进一步对模型继续微调,用附件1中的数据集进行再训练。
确定方向过程
针对完全没有基础的同学们
1.确定机器学习的应用领域有哪些
2.查找机器学习的算法应用有哪些
3.确定想要研究的领域极其对应的算法
4.通过招聘网站和论文等确定具体的技术
5.了解业务流程,查找数据
6.复现经典算法
7.持续优化,并尝试与对应企业人员沟通心得
8.企业给出反馈