由于FPN和DSSD网络结构比较相似,且发布时间非常相近,所以放一起解读
按时间来算FPN是先于DSSD在arxiv上发布的,FPN第一版是2016年12月9日,DSSD第一版是2017年1月23日,前后相差一个月。
YOLO系列其他文章:
- YOLOv1通俗易懂版解读
- SSD算法解读
- YOLOv2算法解读
- YOLOv3算法解读
- YOLOv4算法解读
- YOLOv5算法解读
文章目录
- 1、FPN
- 1.1 算法概述
- 1.2 FPN细节
- 2、DSSD
- 2.1 算法概述
- 2.2 DSSD细节
- 3、FPN与DSSD对比
1、FPN
论文:Feature Pyramid Networks for Object Detection
作者:Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, Serge Belongie
链接:https://arxiv.org/abs/1612.03144
1.1 算法概述
SSD利用不同层的特征图进行不同尺寸的目标预测,又快又好。这篇文章首先也采用了这种思路:在不同深度的特征层上预测不同尺寸的目标。但是SSD为了预测小目标,就得把比较低的层拿出来预测,这样的话就很难保证有很强的语义特征,所以作者就想着,为什么不把高层的特征再传下来,补充低层的语义,这样就可以获得高分辨率、强语义的特征,有利于小目标的检测。作者通过将FPN与Faster R-CNN结合起来,AR直接提升8个点。COCO-style方式计算的AP提升2.3个点,PASCAL-style计算的AP提升3.8个点。
1.2 FPN细节
直接引入论文中的图说明现如今检测算法利用特征图做检测的方式。
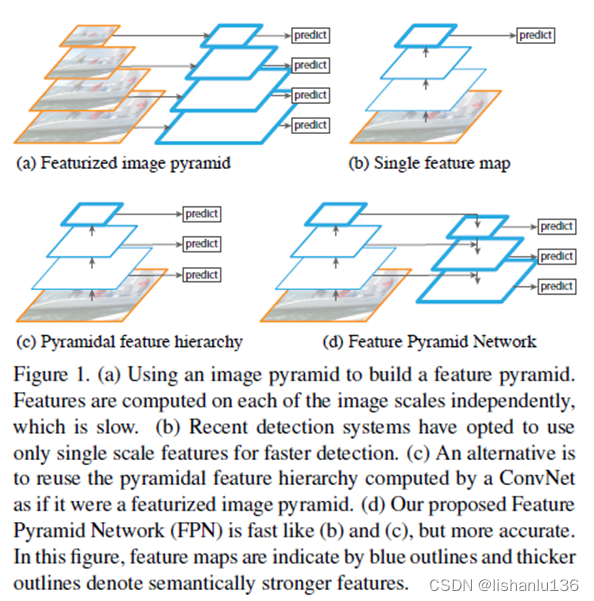
图(a)是通过多尺度变换图片,然后对得到一系列图片提取特征形成的特征金字塔;图(b)就是利用最后一层特征图做预测的方式;图©就是单纯利用多个层级的特征做预测,SSD算法就是采用这种方式;图(d)就是本文提出的FPN,它还有一个top-to-down对多个层级进行融合的过程,并且也是多个特征层多预测。
融合的方式如下,小特征图通过双线性插值完成上采样操作与之前的大特征图相加融合形成新的大特征图。

2、DSSD
论文:DSSD: Deconvolutional Single Shot Detector
作者:Cheng-Yang Fu, Wei Liu, Ananth Ranga, Ambrish Tyagi, Alexander C. Berg
链接:https://arxiv.org/abs/1701.06659
2.1 算法概述
DSSD基于SSD进行改进,将SSD的主干网络换成了提取特征能力更强的ResNet101,也像FPN一样,对SSD的多个特征进行了融合。只是DSSD在从小分辨率特征图变换到大特征图用的操作是反卷积。通过这两个改进,DSSD513在VOC2007测试集上实现了81.5%mAP,VOC2012测试集达到了80.0%mAP,在COCO测试集上是33.2%mAP。
2.2 DSSD细节
直接看DSSD和SSD对比的网络结构图
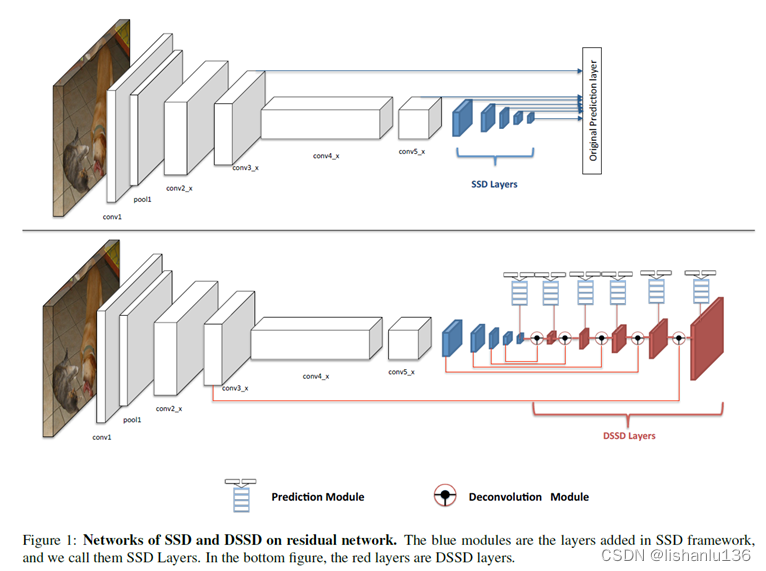
大体上看特征融合的方式和FPN非常像,都是一个top-to-down的过程,最后多个特征图输出预测结果。但作者设计了两个小模块,一个是Prediction Module,一个是Deconvolution Module。
-
Prediction Module
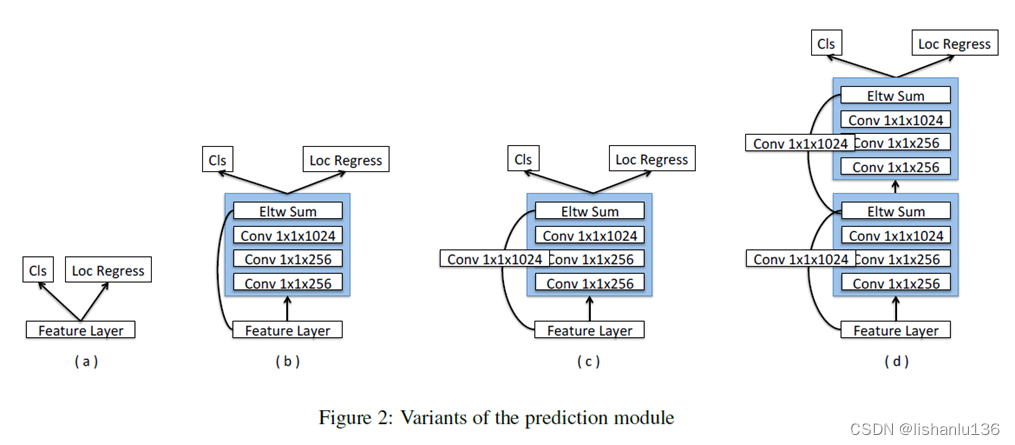
作者说加这个模块是因为MS-CNN指出提升每个子任务网络的表现可以提高准确性,所以作者为每个预测层添加一个残差块,这个有一点效果吧。通过消融实验也证明©的效果最好。作者在最后提出,加PM是为了防止梯度直接流入Res-Net主干。 -
Deconvolution Module
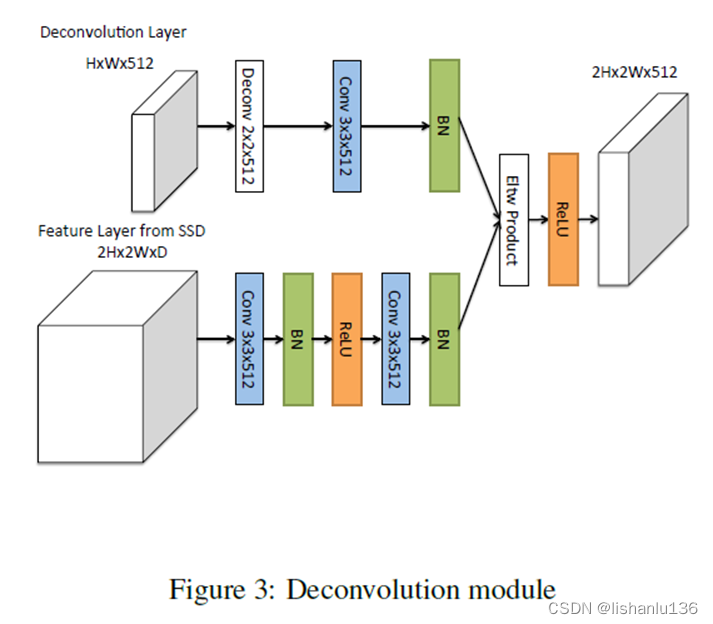
可以看到这个Deconvolution Module不是单纯的将小特征图经过一个反卷积操作然后和大特征图相加融合(FPN是单纯上采样然后相加融合);对于小特征图经过一个反卷积操作后,又经过一个3x3卷积操作,同样的对于大特征图还经过3x3两个卷积操作,然后才是两个特征图做元素相乘操作的融合得到新的大特征图。
3、FPN与DSSD对比
相同点:
均是改进检测算法框架的Neck特征融合增强部分,对检测小目标的性能均有比较大的提升。
不同点:
FPN是基于Faster R-CNN做的改进实验,当然FPN也是通用的,它只是单纯的将小特征图上采样扩大分辨率然后与大特征图相加融合,而DSSD是基于SSD做的改进实验,里面的Deconvolution Module也是做特征融合,也可以通用到其他主干网络,但它的融合方式比FPN更复杂一点,融合之前进行了两个卷积操作,而且是元素相乘的融合方式。其次,DSSD还改进了SSD算法的检测头。