SDS与C字符串的区别
二进制安全
C字符串中的字符必须符合某种编码(比如ASCII),并且除了字符串的末尾之外,字符串里面不能包含空字符,否则最先被程序读入的空字符将被误认为是字符串结尾,这些限制使得C字符串只能保存文本数据,而不能保存像图片、音频、视频、压缩文件这样的二进制数据。
虽然数据库一般用于保存文本数据,但使用数据库来保存二进制数据的场景也不少见,因此,为了确保Redis可以适用于各种不同的场景,SDS的API都是二进制安全的(binary-safe),所有SDS API都会以处理二进制的方式来处理SDS存放在buf数组里的数据,程序不会对其中的数据做任何限制、过滤、或者假设,数据在写入时是什么样的,它被读取时就是
什么样的。这也是将SDS的buf属性称为字节数组的原因——Redis不是用这个数组来保存字符,而是用它来保存一系列二进制数据.
通过使用二进制安全的SDS,而不是C字符串,使得Redis不仅可以保存文本数据,还可以保存任意格式的二进制数据
例子
举个例子,如果有一种使用空字符来分割多个单词的特殊数据格式,
如图所示,那么这种格式就不能使用C字符串来保存,因为C字符串所用
的函数只会识别出其中的"Redis",而忽略之后的"Cluster"

例如,使用SDS来保存之前提到的特殊数据格式就没有任何问题,因为
SDS使用len属性的值而不是空字符来判断字符串是否结束,如图所示

兼容部分C字符串函数
虽然SDS的API都是二进制安全的,但它们一样遵循C字符串以空字符结尾的惯例:这些API总会将SDS保存的数据的末尾设置为空字符,并且总会在为buf数组分配空间时多分配一个字节来容纳这个空字符,这是为了让那些保存文本数据的SDS可以重用一部分<string.h>库定义的函数
例子
举个例子,如图所示,如果有一个保存文本数据的SDS值sds,那么我们就可以重用<string.h>/strcasecmp函数,使用它来对比SDS保存的字符串和另一个C字符串:
strcasecmp(sds->buf, "hello world");
这样Redis就不用自己专门去写一个函数来对比SDS值和C字符串值了。
与此类似,还可以将一个保存文本数据的SDS作为strcat函数的第二个参数,将SDS保存的字符串追加到一个C字符串的后面:
strcat(c_string, sds->buf);
这样Redis就不用专门编写一个将SDS字符串追加到C字符串之后的函数了。通过遵循C字符串以空字符结尾的惯例,SDS可以在有需要时重用<string.h>函数库,从而避免了不必要的代码重复

总结比较

链表
概述
链表提供了高效的节点重拍能力,以及顺序性的节点访问方式,并且可以通过增删节点来灵活地调整链表的长度。作为一种常用的数据结构,链表内置在很多高级的变成语言里面,因为Redis使用的C语言并没有内置这种数据结构,所以Redis构建了自己的链表实现。链表在Redis中的应用
非常广泛,比如列表键的底层实现之一就是链表。当一个列表键包含了数量比较多的元素,又或者列表中包含的元素都是比较长的字符串时,Redis就会使用链表作为列表键的底层实现。
除了链表键之外,发布与订阅、慢查询、监视器等功能也用到了链表,Redis服务器本身还使用链表来保存多个客户端的状态信息,以及使用链表来构建客户端输出缓冲区(output buffer)
例子
举个例子,以下展示的integers列表键包含了从1到1024共1024个整数:
integers列表键的底层实现就是一个链表,链表中的每个节点都保存了一个整数值。
redis> LLEN integers
(integer) 1024
redis> LRANGE integers 0 10
1) "11"
2) "10"
3) "7"
4) "6"
5) "5"
6) "4"
7) "3"
8) "2"
9) "1"
10) "0"
链表和链表节点的实现
每个链表节点使用一个adlist.h/listNode结构来表示:
typedef struct listNode {
// 前置节点
struct listNode *prev;
// 后置节点
struct listNode *next;
// 节点的值
void *value;
}listNode;
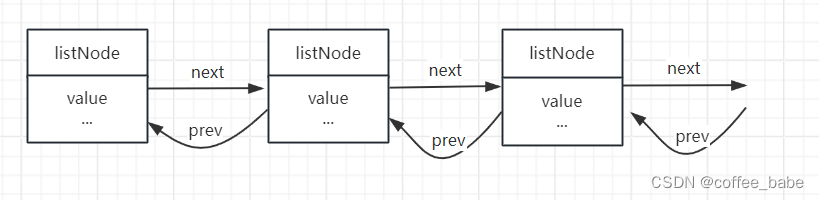
多个listNode可以通过prev和next指针组成双端链表,如图
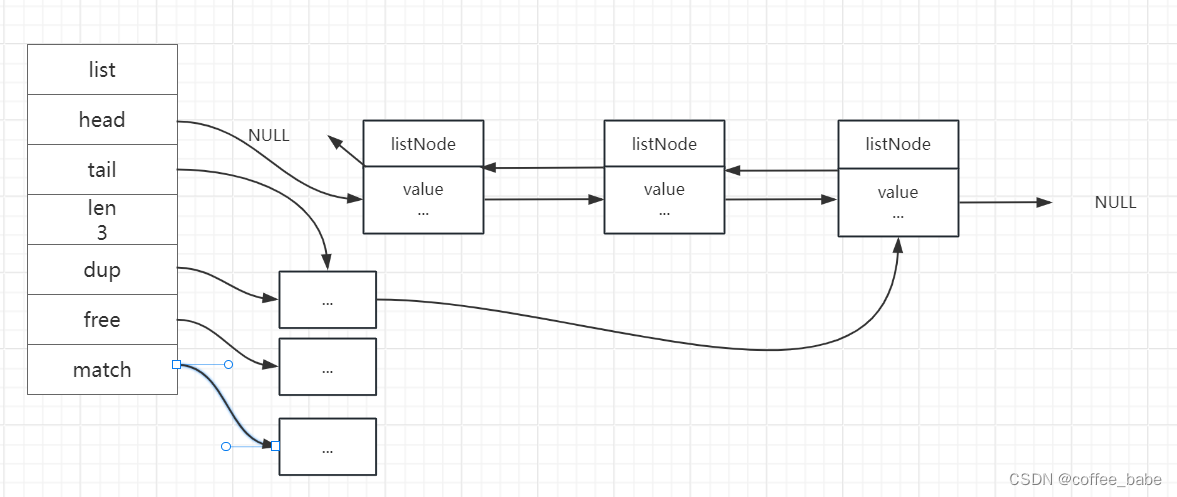
虽然仅仅使用多个listNode结构就可以组成链表,但使用adlist.h/list来持有链表的话,操纵起来会更方便。list结构为链表提供了表头指针head、表尾指针tail,以及链表长度计数器len,而dup、free和match成员则是用于实现多态链表所需的类型特定函数:
- 1.dup函数用于复制链表节点所保存的值
- 2.free函数用于释放链表节点所保存的值
- 3.match函数则用于对比链表节点所保存的值和另一个输入值是否相等
typedef struct list {
//表头节点
listNode *head;
// 表尾节点
listNode *tail;
// 链表所包含的节点数量
unsigned long len;
// 节点值赋值函数
void *(*dup)(void *ptr);
// 节点值释放函数
void *(*free)(void *ptr);
// 节点值对比函数
int (*match)(void *ptr, void *key);
}list;
如图是由一个list结构和三个listNode结构组成的链表
特点总结
Redis的链表实现的特性可以总结如下:
- 1.双端:链表节点带有prev和next指针,获取某个节点的前置节点和后置节点的复杂度都是O(1)
- 2.无环:表头节点的prev指针和表尾节点next指针都指向NULL,对链表的访问以NULL为终点
- 3.带有表头指针和表尾指针:通过list结构的head指针和tail指针,程序获取链表的表头节点和表尾节点的复杂度为O(1)
- 4.带链表长度计数器:程序使用list结构的len属性来对list持有的链表节点进行计数,程序获取链表中节点数量的复杂度为O(1)
- 5.多态:链表节点使用void*指针来保存节点值,并且可以通过list结构的dup、free、match三个属性为节点值设置类型特定函数,所以链表可以用于保存各种不同类型的值