一、常见的反爬介绍
基于身份识别的反爬:1.User-agent 2.Referer 3.Captcha 验证码 4.必备参数
基于爬虫行为的反爬:1.单位时间内请求数量超过一定阈值 2.相邻两次请求之间间隔小于一定阈值3.蜜罐陷阱
通过对数据加密进行反爬:1.对文字加密 2.对请求参数加密 3.对响应数据加密
二、文字加解密
(一)常见文字加解密方式
1.通过对数据图片化进行反爬
2.对文字进行编码 unicode, HTML 字符实体
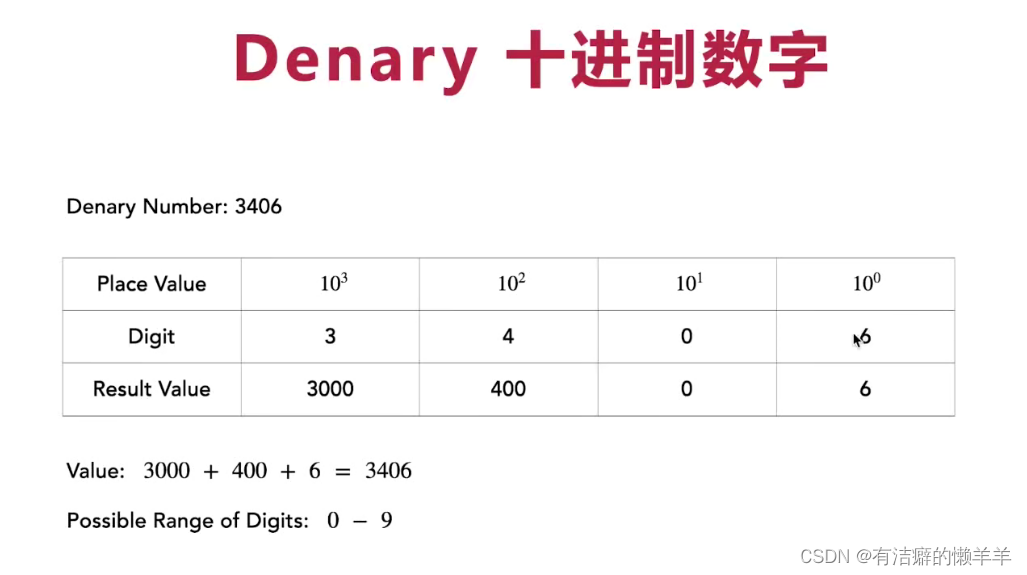
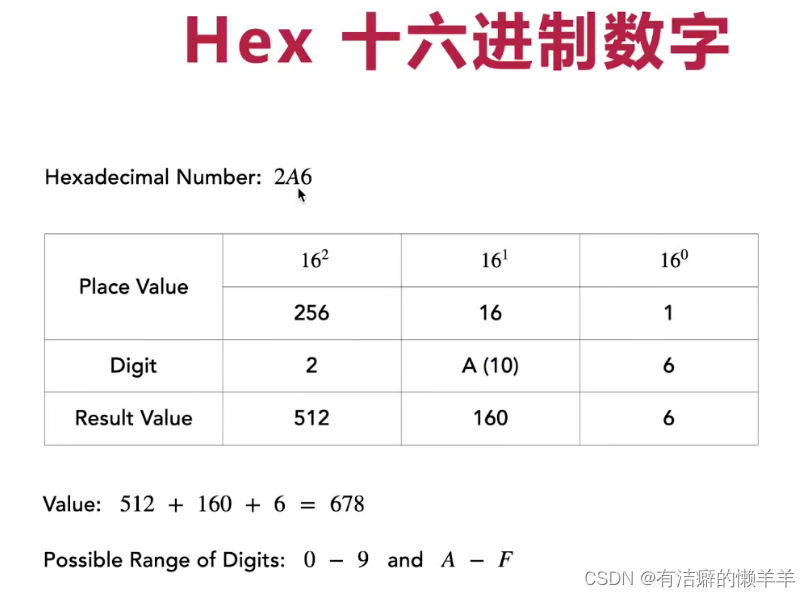
(二)二进制与十六进制

以下为用代码表示方法:
num = 20
# 16进制表示
print(hex(num))
# 二进制表示
print(bin(num))
num2 = 0b10001
print(num2)
num3 = 0xA2
print(num3)(三)ASCII&UTF-8&Unicode编码
1.字符集:(1)每一个字符在计算机里都被保存为二进制的编码(2)成千上万组这种关系就组成了字符集
2.常见的字符集:ASCII,UTF-8,Unicode, GBK
3.ASCII:(1) English (2) 7-bits
# 转为ASCII编码形式
num = ord("A")
print(num)
# 查看二进制形式
print(bin(num))
# 传进去ASCII码转为字符
ch1 = chr(65)
print(ch1)
ch2 = chr(0b1000010)
print(ch2)4.Unicode:(1) 世界各地语言 (2)固定长度, 2 bytes
5.UTF-8:(1)基于unicode编码的可变长度的格式 (2)1 bytes - 4 bytes
6.GBK:中文
(四)Python实现EncodeDecode编码转换
s1 = "中"
s2 = s1.encode("utf-8")
print(s2)
s3 = s1.encode("unicode-escape")
print(s3)
s4 = b'\xe4\xb8\xad'
# 将二进制的格式转成文字
s5 = s4.decode("utf-8")
print(s5)
s6 = b'\\u4e2d'
s7 = s6.decode("unicode-escape")
print(s7)(五)破解Unicode与HTML字符实体加密
import requests
url = "http://127.0.0.1:5000/api/C12L06"
headers = {
"User-Agent": "xxxxxxxxxxxxxx"
}
res = requests.get(url, headers=headers)
print(res.text)
# 进行解码
print(res.content.decode("unicode-escape"))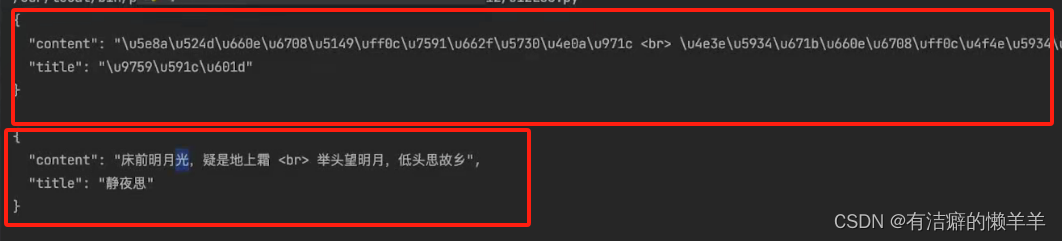
import requests
import html
url = "http://127.0.0.1:5000/api/C12L06b"
headers = {
"User-Agent": "xxxxxxxxxxxxxx"
}
res = requests.get(url, headers=headers)
print(res.text)
# 进行解码
print(html.unescape(res.text))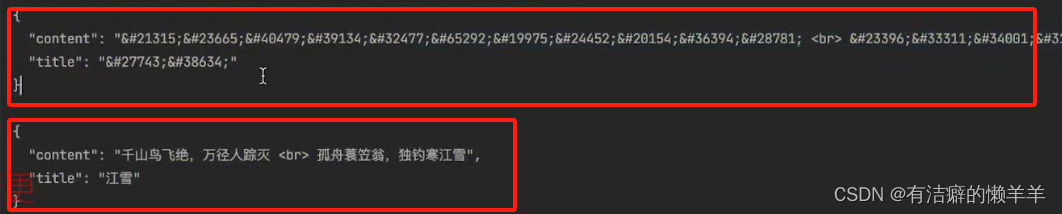
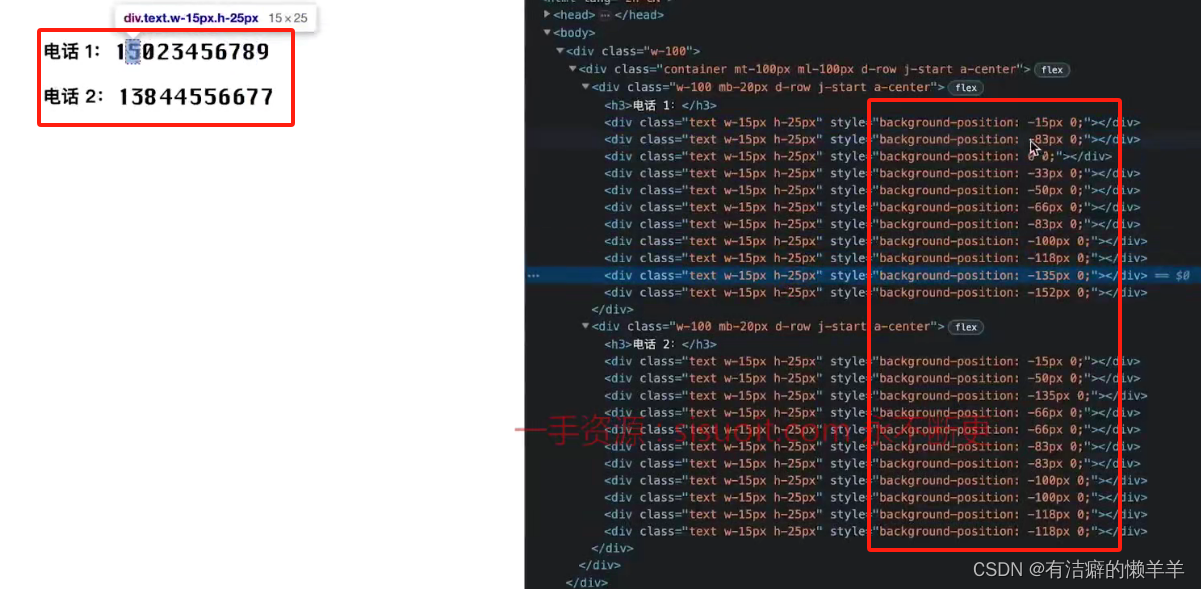
(六)破解CSS偏移文字加密
import requests
from lxml import etree
url = "http://127.0.0.1:5000/C12L07"
headers = {
"User-Agent":"xxx"
}
res = requests.get(url, headers=headers)
mapping = {
"0":"0",
"-15px":"1",
"-33px":"2",
"-50px":"3",
"-66px":"4",
"-83px":"5",
"-100px":"6",
"-118px":"7",
"-135px":"8",
"-152px":"9"
}
tree = etree.HTML(res.text)
items = tree.xpath('/html/body/div/div/div[1]/div/@style')
number = ""
for item in items:
value = item.split(" ")[1]
value = mapping[value]
number += value
print(number)
items2 = tree.xpath('/html/body/div/div/div[2]/div/@style')
number2 = ""
for item in items2:
value = item.split(" ")[1]
value = mapping[value]
number2 += value
print(number2)(七)实践:自如ZiRoom获取租房信息

上述图片右侧的红框是链接:点开链接为图片形式:

import requests
import re
from lxml import etree
import base64
import json
url = 'https://www.ziroom.com/z/'
headers = {
"User-Agent":"xxxx"
}
res = requests.get(url, headers=headers)
tree = etree.HTML(res.text)
style = tree.xpath('/html/body/section/div[3]/div[2]/div[1]/div[2]/div[2]/span[2]/@style')[0]
exp = re.compile('background-image: url\((.*?)\)', re.S)
img_url = "https:"+exp.findall(style)[0]
img_res = requests.get(img_url, headers=headers)
with open('./C12LO8/img.png', 'wb') as f:
f.write(img_res.content)
url = "https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=xxxxxx&client_secret=xxxxx"
payload = ""
headers = {
'Content-Type': 'application/json',
'Accept': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
access_token = response.json()["access_token")
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic"
f = open('./C12LO8/img.png', 'rb')
img = base64.b64encode(f.read())
params = {"image":img}
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
if response:
result = response.json()["words_result"][0]["words"]
print(result)
mappings = {
"-0px": result[0],
"-21.4px": result[1]
"-42.8px": result[2],
"-64.2px": result[3],
"-85.6px": result[4],
"-107px": result[5],
"-128.4px": result[6],
"-149.8px": result[7],
"-171.2px": result[8],
"-192.6px": result[9]
}
items = tree.xpath('div[@class="Z_list-box"]/div')
for item in items:
try:
title = item.xpath('./div[@class="info-box"]//a/text()')[0]
nums = item.xpath('.//span[@class="num"]/@style')
price = ""
for num in nums:
price += mappings[num.split("background-position:")[1].strip()]
print(title, price)
except:
print("bannar")